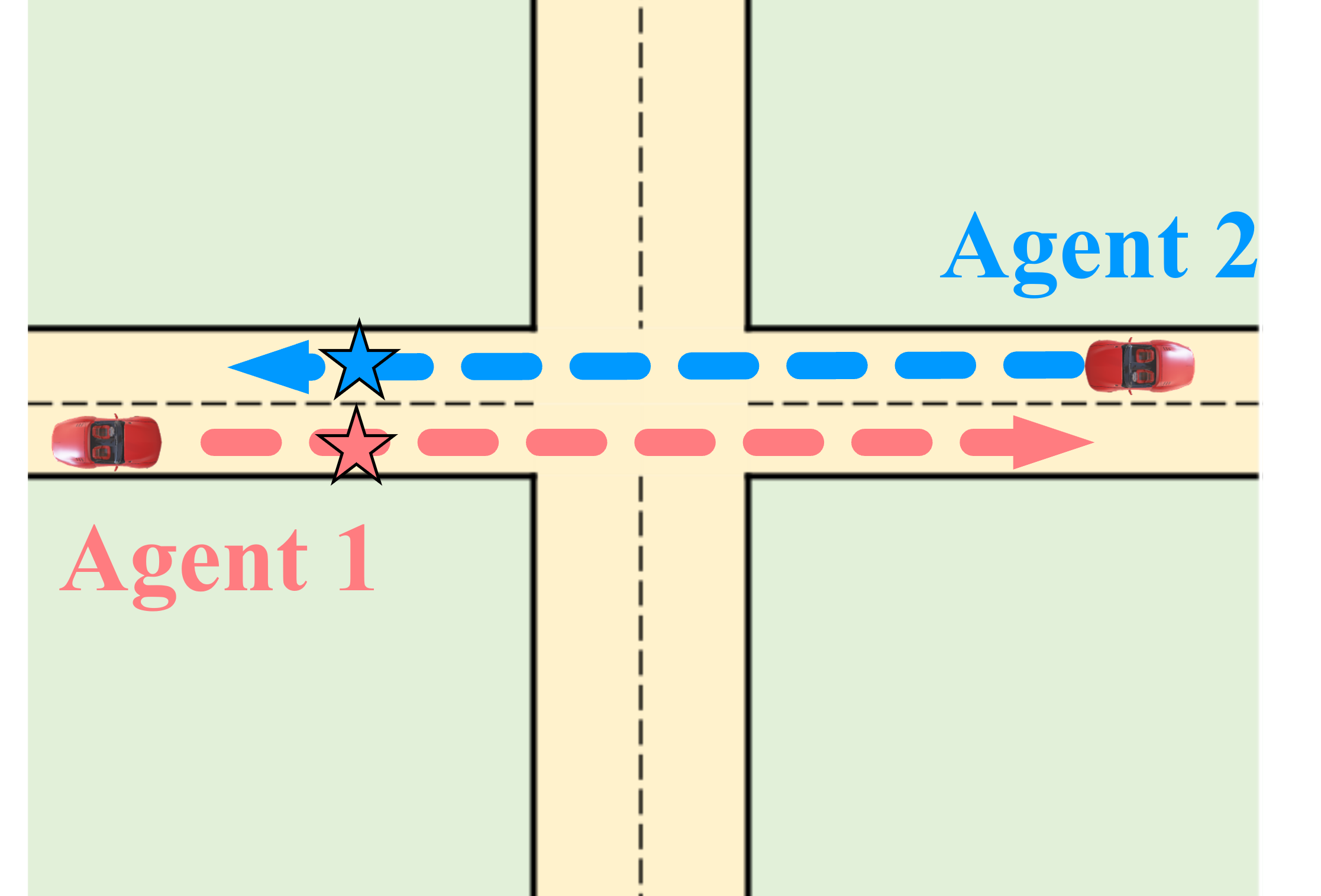
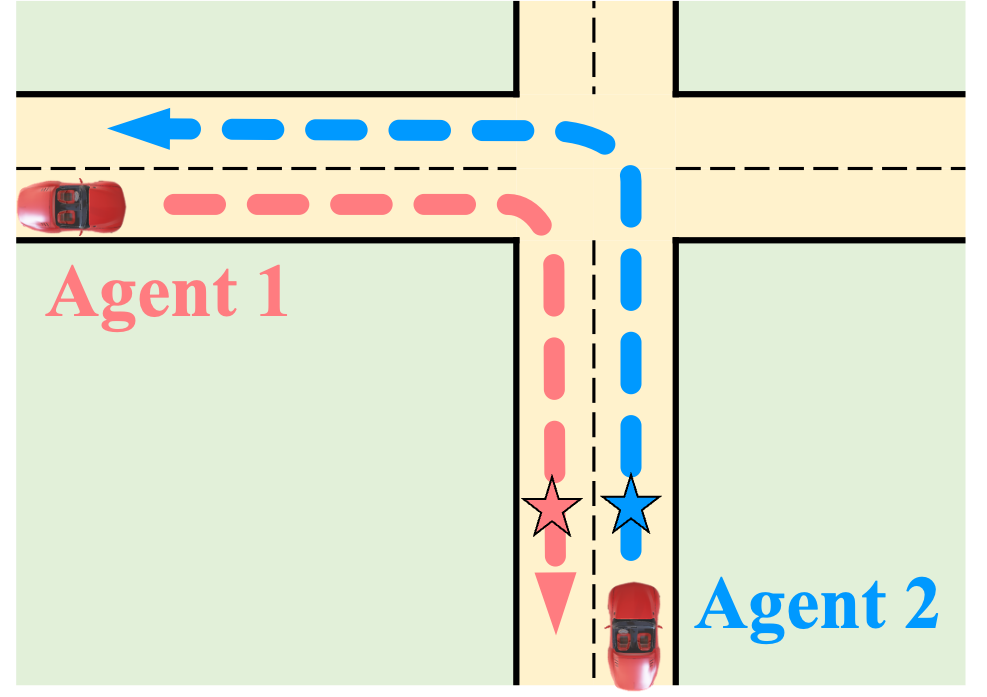
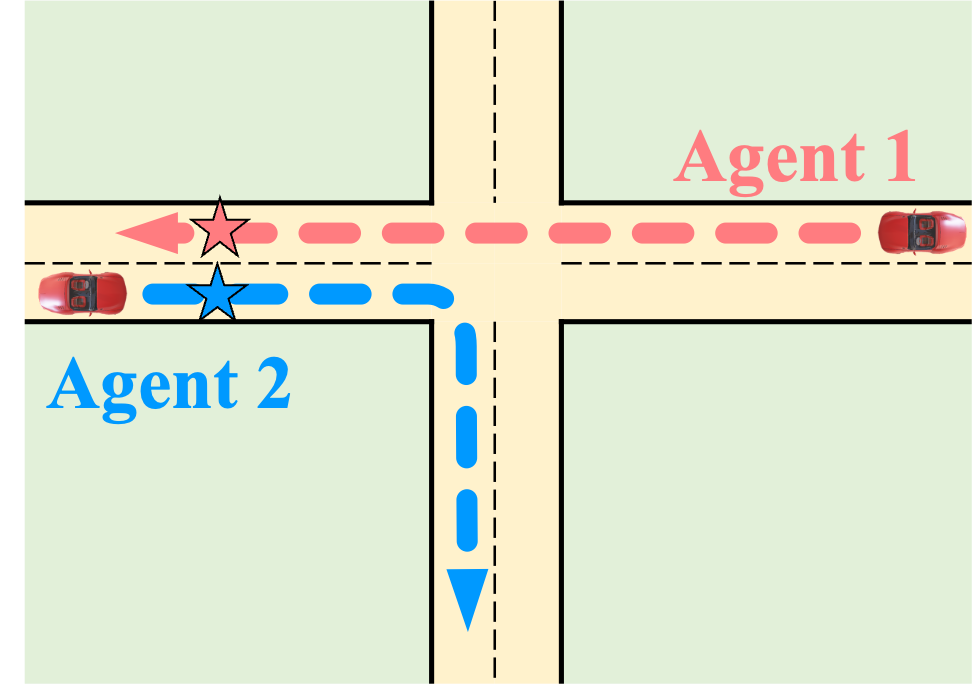
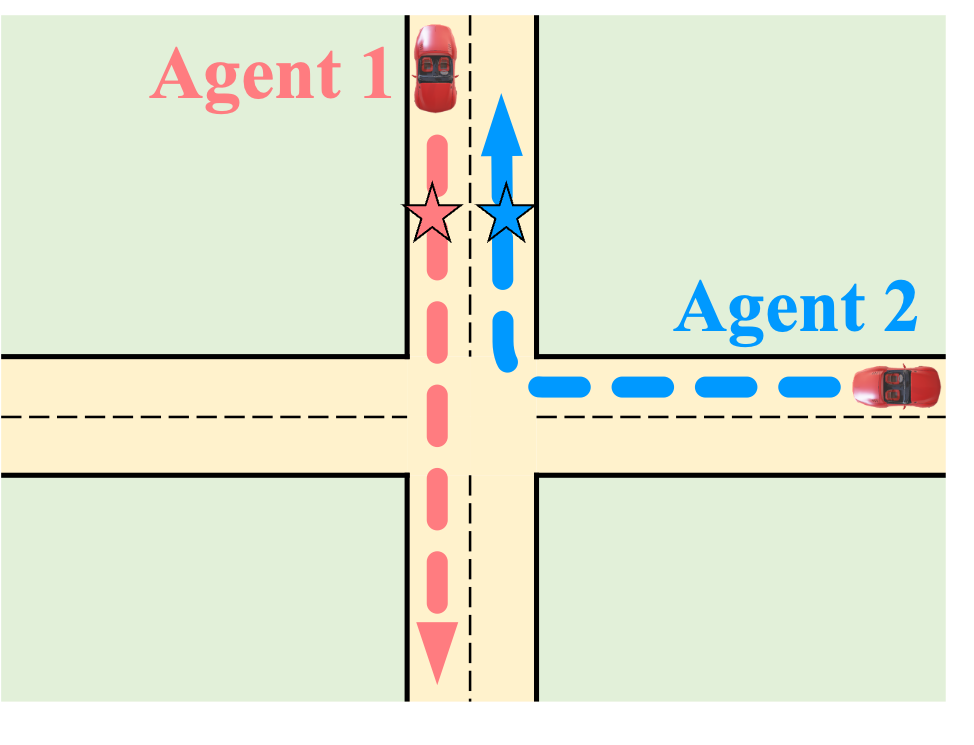
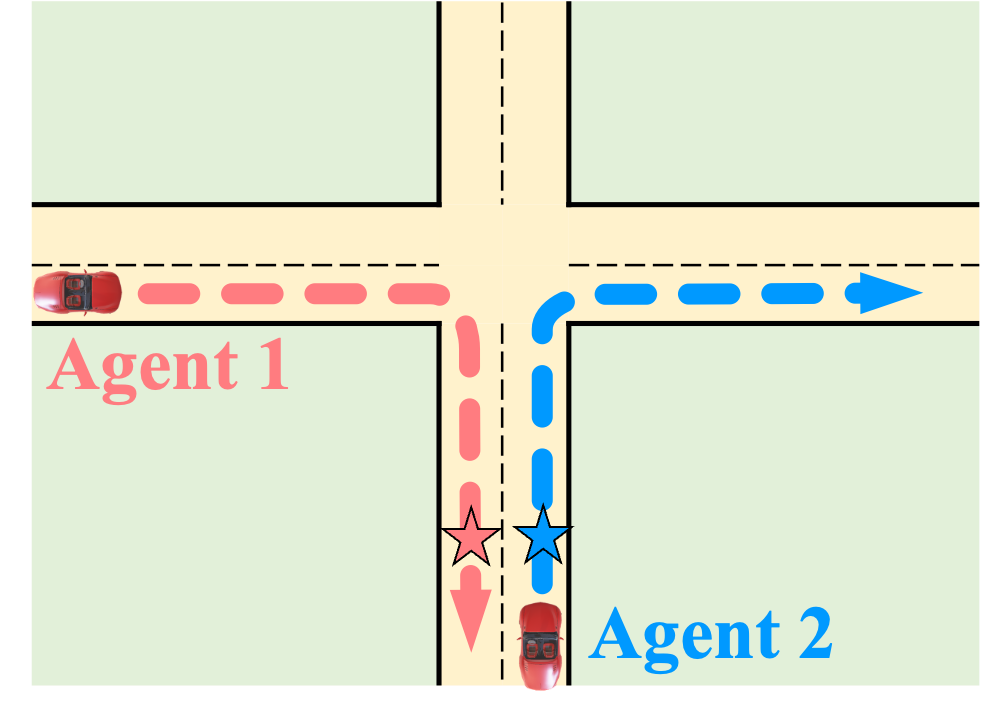
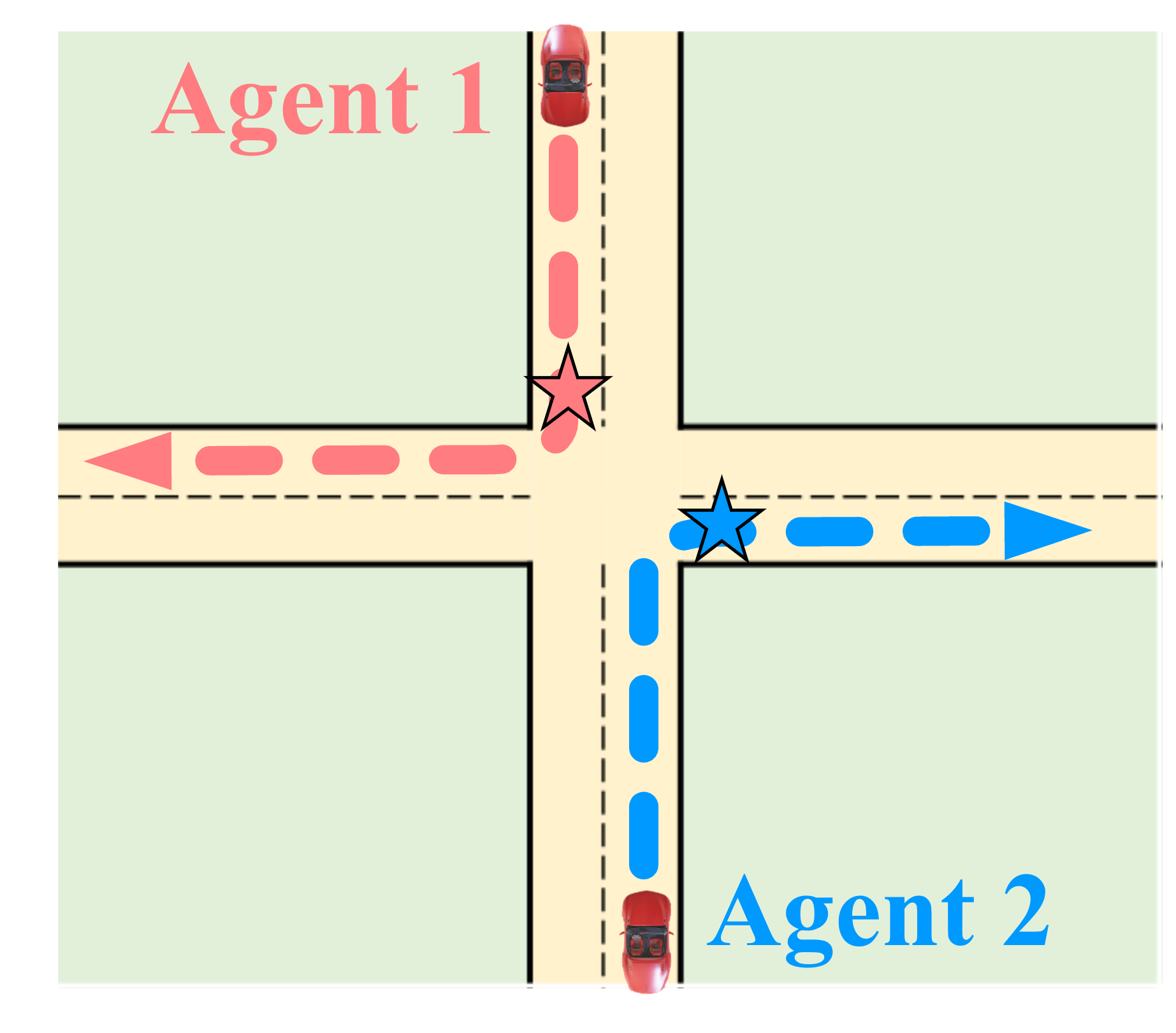
ShareVerse: Collaborative Video Generation for Shared World Modeling. ShareVerse empowers distributed agents to collaboratively synthesize
a globally consistent virtual environment. We bridge isolated generative priors through two core mechanisms: (1) implicit cross-agent interaction, which
resolves visual conflicts during concurrent exploration (red/blue vehicles); and (2) a global Spatiotemporal Memory Cache, which guarantees long-term
environmental permanence during asynchronous revisitation (green vehicle).
Framework Overview
(a) Dataset
(b) Pipeline
(c) Method
Experimental Results
For each group, the top row sequentially shows the global point cloud, local point cloud, and a pair of certain frames. The bottom row contains the trajectory map and two videos: the left video corresponds to agent 1, and the right one corresponds to agent 2.
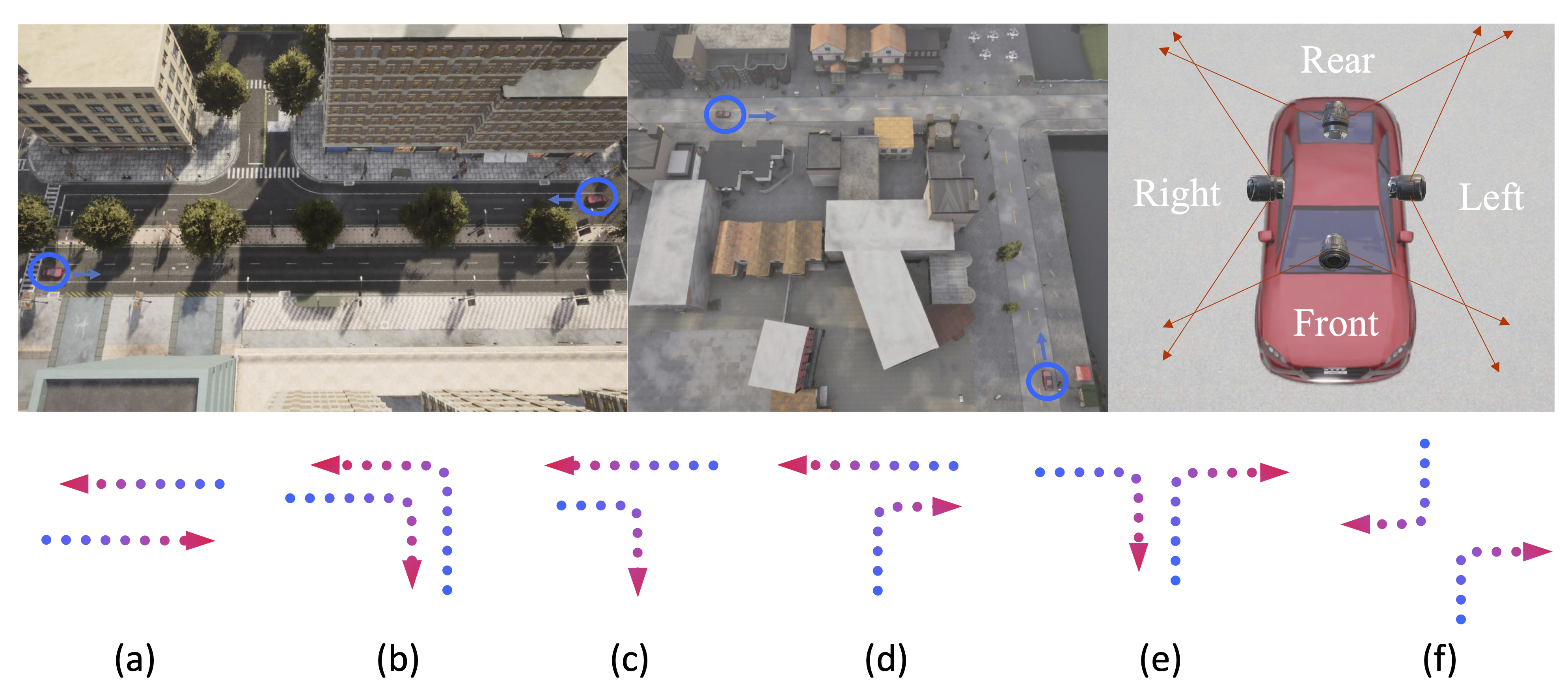 (a) Dataset
(a) Dataset
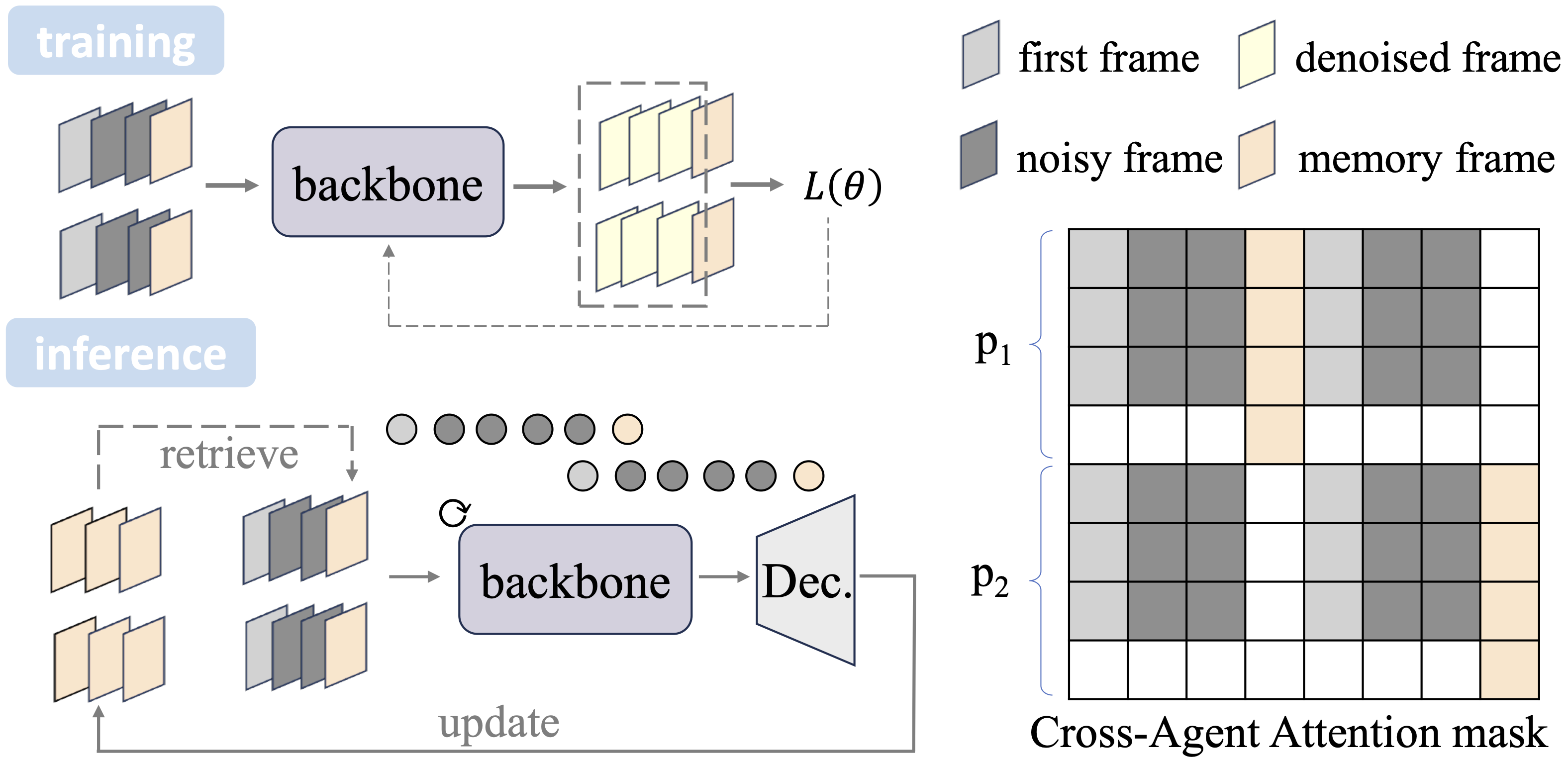 (b) Pipeline
(b) Pipeline
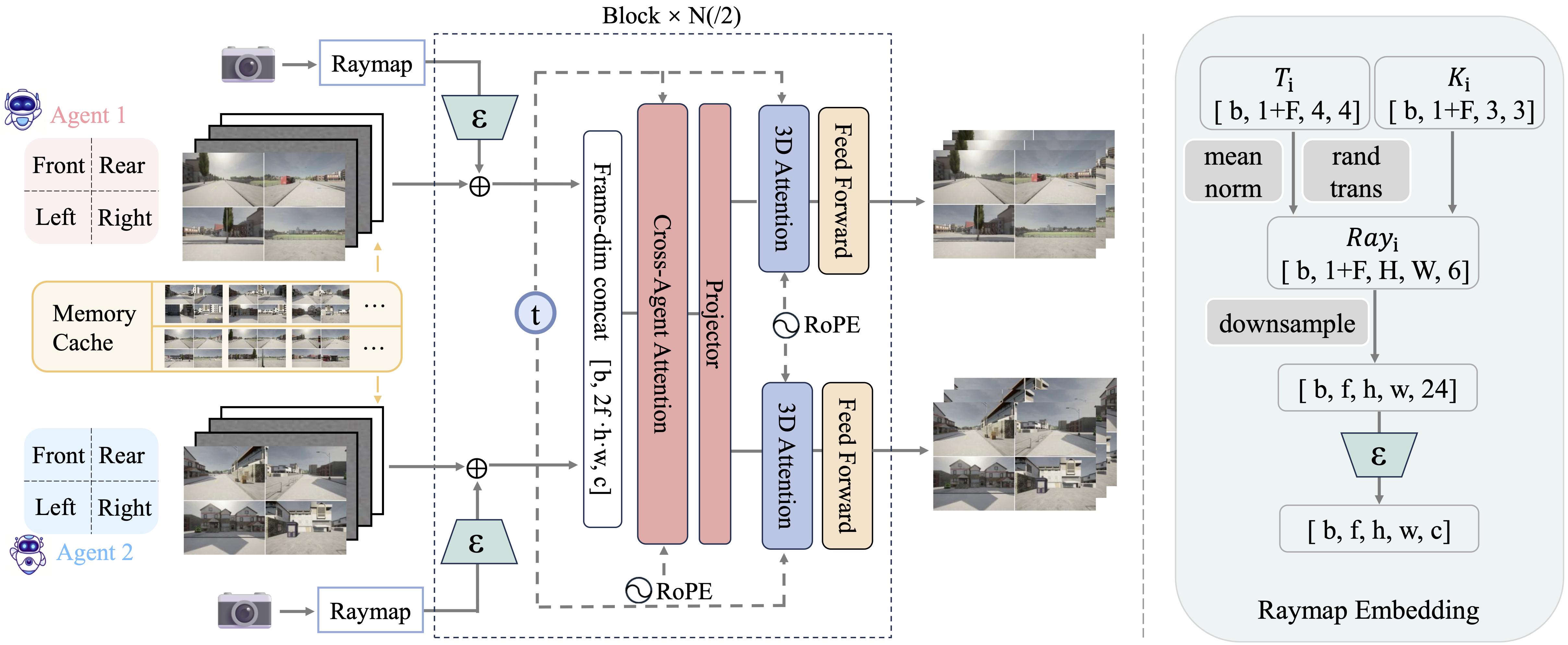 (c) Method
(c) Method